Types of Deep Neural NetworksWhat are the various types of deep networks and how are they used?
|

|
As you might imagine, multiple configurations of artificial neurons are possible. Some of the more important neural network variations are briefly cataloged below. The first type, Convolutional Neural Network (CNN), will only be briefly introduced here, but is so important for image-based applications that it will be covered more extensively in several subsequent Q&As.
Convolutional Neural Networks (CNNs)
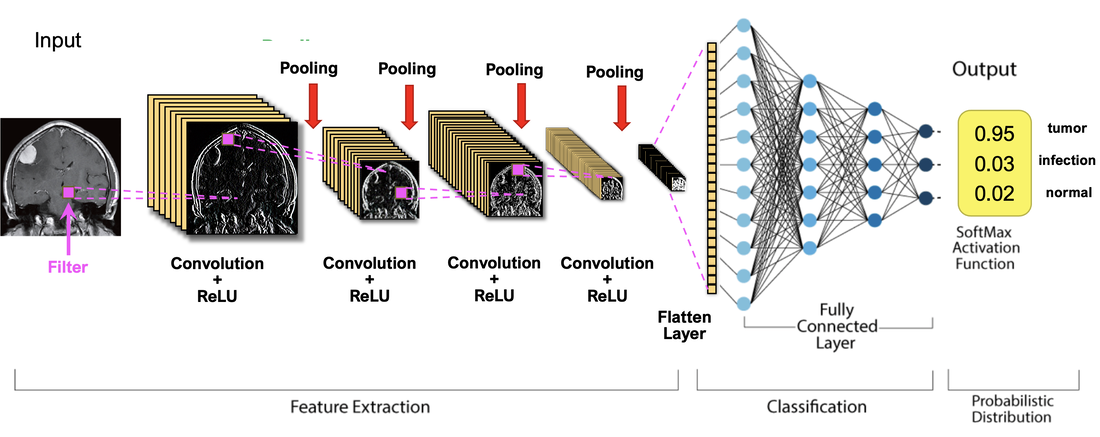
CNN is the configuration most widely used for MRI and other image processing applications. Data is typically input as 2D or 3D arrays of pixels and initial computational phases are restricted to operations on neighboring pixels.
Convolution involves a sliding multiplication and addition of regional data points by a small (~5x5) array of numbers called a kernel or filter. By using sets of different kernels (such as ones that emphasize edges or shapes) a set of regional feature maps is produced. The next step, called subsampling or pooling, shrinks the size of each feature map, typically taking the maximum value in each 2x2 pixel group. The convolution-pooling process may be repeated several times, producing ever smaller "feature of feature" maps. In the final stage, known as vectorization or flattening, all the resultant 2-dimensional arrays are converted into a single long chain of numbers (i.e., a "vector"). The vectorized feature maps then serve as inputs into a fully connected neural network whose output may then be fed back in training to adjust weighting parameters in the convolutional part of the network or used to produce a final result (such as tissue segmentation or classification).
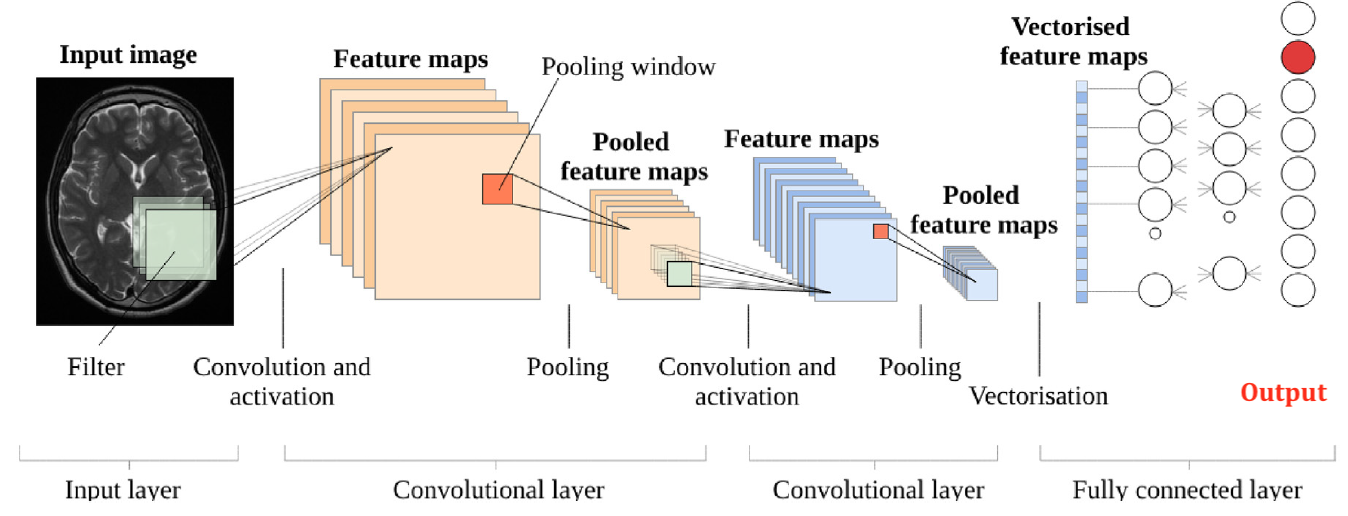
Building blocks of a CNN
Two basic two types of CNN architectures can be distinguished based on the connection modes between convolutional layers. The first type of CNN architecture (pictured above) connects different convolutional layers in series. Examples include such well-known configurations as AlexNet, VGGNet, and ZFNet. The second architecture connects convolutions in parallel, characterized by the inception modules used by GoogleNet and its progeny. An inception module consists of multiple parallel convolutional layers, each with a different filter size. The intuition behind this design is that different filter sizes are better suited for detecting features of different scales, which is useful for recognizing objects of various sizes and shapes.
Encoder-Decoder Networks
Encoder-decoder networks are a specific form of CNN widely used for image segmentation, co-registration, and artifact reduction. They typically have a "U-configuration", with an initial contracting path (the encoder) followed by an expansion path (the decoder). Full dimensional images input into the encoder portion are reduced in size via a CNN-type mechanism into lower dimensional data, thus compressing the feature maps. These maps are then re-expanded in the decoder portion back to full size containing the most meaningful features. Loss of spatial resolution can be overcome by inserting skip connections between the sides to pass through important details to the output image. The U-net network (pictured below) and its variants are the most widely used encoder-decoder networks for medical imaging.
Encoder-decoder networks are a specific form of CNN widely used for image segmentation, co-registration, and artifact reduction. They typically have a "U-configuration", with an initial contracting path (the encoder) followed by an expansion path (the decoder). Full dimensional images input into the encoder portion are reduced in size via a CNN-type mechanism into lower dimensional data, thus compressing the feature maps. These maps are then re-expanded in the decoder portion back to full size containing the most meaningful features. Loss of spatial resolution can be overcome by inserting skip connections between the sides to pass through important details to the output image. The U-net network (pictured below) and its variants are the most widely used encoder-decoder networks for medical imaging.
Basic U-net architecture.
Generative Adversarial Networks (GANs)
GANs consist of two competing components: (1) the Generator, a deconvolutional network that uses random noise and interpolation to generate "fake" but realistic-looking images, and (2) the Discriminator, a conventional CNN previously trained with supervised learning to identify real images at a certain level of accuracy.
In operation, images are randomly sent to the discriminator, which must then decide which are real and which have been generated. If its judgment is wrong (i.e. a fake image being mistaken for real), the Discriminator will learn from its error and improve on subsequent runs. If its judgment is correct, this information will be sent back to the Generator to help it develop better "fake" images. Through iteration, the performance of both components improve, as does the GAN as a whole. Applications in MRI include image synthesis, reconstruction, segmentation, co-registration, and production of "super-resolution" images.
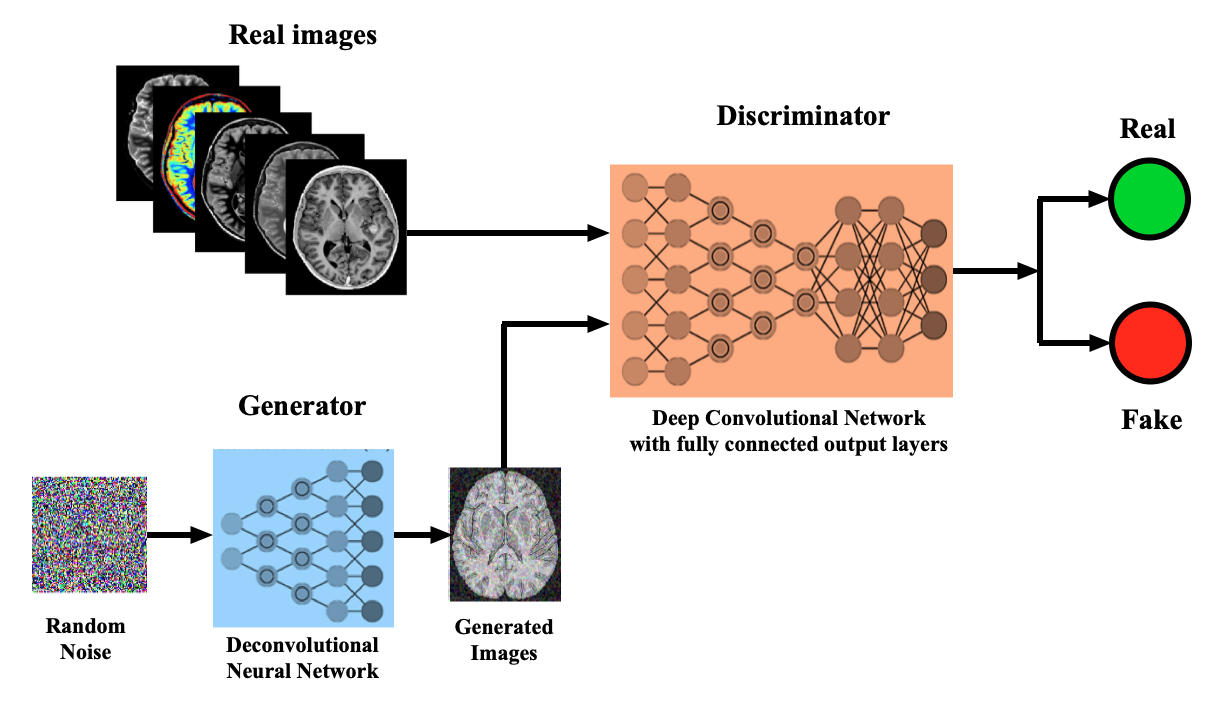
Structure of a Generative Adversarial Network (GAN), where the Generator tries to fool the Discriminator between identifying "real" and "fake" images, with both learning iteratively through the process.
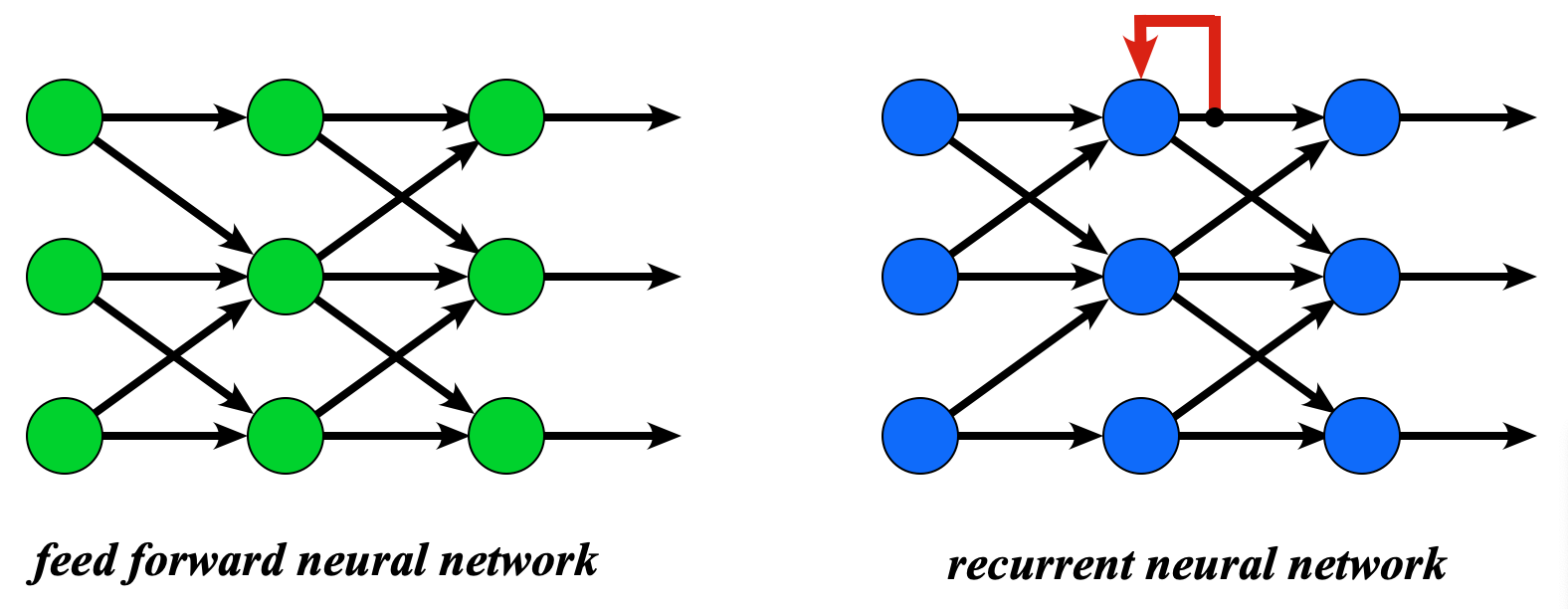 Nodes in an RNN can feed recent outputs back
Nodes in an RNN can feed recent outputs back onto themselves or others
Recurrent Neural Networks (RNNs)
RNNs differ from standard "feed forward" neural networks in that they contain data feedback loops. This feedback serves as a type of "memory" allowing them to use recent outputs as updated inputs for subsequent calculations. RNNs are useful in the analysis of sequentially acquired data, including time series and speech processing. For example, the location of the cardiac septum on cine MRI depends on its immediately prior position; the next word in a radiology report depends on the previous word.
RNNs differ from standard "feed forward" neural networks in that they contain data feedback loops. This feedback serves as a type of "memory" allowing them to use recent outputs as updated inputs for subsequent calculations. RNNs are useful in the analysis of sequentially acquired data, including time series and speech processing. For example, the location of the cardiac septum on cine MRI depends on its immediately prior position; the next word in a radiology report depends on the previous word.
Simple feedback loops can only allow a handful of data time steps to be retained and used. To overcome this limitation more complex RNN configurations, including Long Short-Term Memory (LSTM) and Gated Recurrent Units (GRUs), have been developed that allow retention of data over many thousands of time points. Bi-directional RNNs are also possible, where the output of later nodes is fed back to update past nodes in an iterative fashion. In recent years, Transformer Neural Networks (TNNs) discussed below have largely replaced RNNs and LSTMs for many applications.
|
Transformer Neural Networks (TNNs)
TNNs, also known simply as Transformers, were developed in 2017 by the Google Brain research group to improve natural language processing. The wildly popular application, ChatGPT, is based on a transformer architecture. (The letters GPT stand for "Generative Pre-trained Transformer".) Many transformer variations exist, including hybrid forms with CNNs or GANs.
|
|
Transformer networks are different from traditional recurrent neural networks (RNNs) and convolutional neural networks (CNNs) in that they do not use sequential processing or convolutional filters. Instead, they use self-attention mechanisms and parallel processing to handle input sequences.
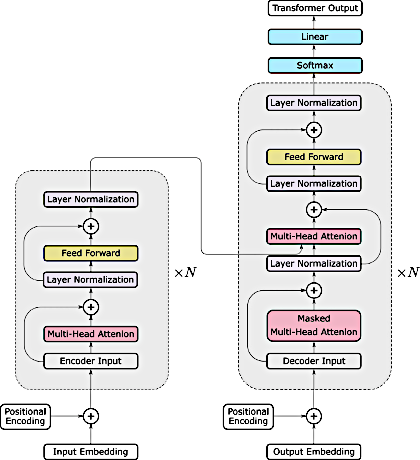 Typical Transformer architecture with encoder on left and decoder on right.
Typical Transformer architecture with encoder on left and decoder on right.(From He et al under CC-BY)
The typical Transformer architecture utilizes an Encoder-Decoder arrangement as shown in the diagram right. Transformers are designed to process data in parallel rather than sequentially, so that information is simultaneously passed between the Encoder and Decoder segments. This parallel architecture means that graphics processing units (GPUs) can be used more efficiently increasing the speed of calculations and training.
Two other characteristic features of Transformer Networks are the use of positional encoding and self-attention. Positional encoding refers to the indexing of words or image segments by original location as they pass through the network. Self-attention refers to the ability of the network to identify the most important features in a data set and their relationships to other data.
Two other characteristic features of Transformer Networks are the use of positional encoding and self-attention. Positional encoding refers to the indexing of words or image segments by original location as they pass through the network. Self-attention refers to the ability of the network to identify the most important features in a data set and their relationships to other data.
A complete description of Transformers is well beyond the scope of this web site, but I suspect you will here more and more about these networks for image-based applications in the future. Due to the large number of pixels, images are usually broken up into multiple small "patches" (say, 16x16 in size) whose relative locations (positional encodings) are remembered by the system and key features identified (by self-attention mechanisms). Some recent examples of the use of Transformers in medical imaging applications (including segmentation, classification, and processing) are provided in the references below.
References
Ali A. Convolutional neural network (CNN) with practical implementation. Wavy AI Research Foundation. Downloaded from https://medium.com/machine-learning-researcher 20 Jan 2022
Ali A. Recurrent neural network and LSTM with practical implementation. Wavy AI Research Foundation. Downloaded from https://medium.com/machine-learning-researcher 20 Jan 2022.
Chartrand G, Cheng PM, Vorontsov E, et al. Deep learning: a primer for radiologists. RadioGraphics 2017; 37:2113-2131. [DOI LINK]
Cheng PM, Montagnon E, Yamashita R, et al. Deep learning: an update for radiologists. RadioGraphics 2021; 41:1427-1445. [DOI LINK]
Dosovitskiy L, Beyer L, Kolesnikov A, et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. ArXiv abs/2010.11929 (2021)
Giacaglia G. How transformers work. Towards Data Science. 10 Mar 2019
He K, Gan C, Li Z, et al. Transformers in medical image analysis. Intelligent Medicine 2023; 3:59-78. [DOI LINK]
Lundervold AS, Lundervold A. An overview of deep learning in medical imaging focusing on MRI. Z Med Phys 2019; 29:102-127. [DOI LINK]
Maier A, Syben C, Lasser T, Riess C. A gentle introduction to deep learning in medical image processing. Z Med Pay 2019; 29:86-101. [DOI LINK]
Moawad AW, Fuentes DT, ElBanan MG, et al. Artificial intelligence in diagnostic radiology: where do we stand, challenges, and opportunities. J Comput Assist Tomogr 2022; 46:78-90. [DOI LINK]
Nicholson C. A beginner’s guide to LSTMs and recurrent neural networks. In: A.I. Wiki. A beginner’s guide to important topics in AI, machine learning, and deep learning. (Downloaded from wiki.pathmind.com 13 Jan 2022)
Siddique N, Paheding S, Elkin CP, Devabhaktuni V. U-Net and its variants for medical image segmentation: a review of theory and applications. IEEE Access 2021:82031-82057. [DOI LINK]
Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need. (2017-6-12). arXiv1706.03762. [DOI LINK] (Original paper describing Transformers)
Willemink MJ, Roth HR, Sandfort V. Two foundational deep learning models for medical imaging in the new era of Transformer Networks. Radiology: Artificial Intelligence 2022; 4(6):e210284. [DOI LINK]
Wolterink JM, Mukhopadhyay A, Leiner T, et al. Generative adversarial networks: a primer for radiologists. RadioGraphics 2021; 41:840-857. [DOI LINK]
Yi Xin, Babyn PS. Generative adversarial network in medical imaging: a review. Medical Image Analysis 2019; 58:101552. [DOI LINK]
Ali A. Convolutional neural network (CNN) with practical implementation. Wavy AI Research Foundation. Downloaded from https://medium.com/machine-learning-researcher 20 Jan 2022
Ali A. Recurrent neural network and LSTM with practical implementation. Wavy AI Research Foundation. Downloaded from https://medium.com/machine-learning-researcher 20 Jan 2022.
Chartrand G, Cheng PM, Vorontsov E, et al. Deep learning: a primer for radiologists. RadioGraphics 2017; 37:2113-2131. [DOI LINK]
Cheng PM, Montagnon E, Yamashita R, et al. Deep learning: an update for radiologists. RadioGraphics 2021; 41:1427-1445. [DOI LINK]
Dosovitskiy L, Beyer L, Kolesnikov A, et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. ArXiv abs/2010.11929 (2021)
Giacaglia G. How transformers work. Towards Data Science. 10 Mar 2019
He K, Gan C, Li Z, et al. Transformers in medical image analysis. Intelligent Medicine 2023; 3:59-78. [DOI LINK]
Lundervold AS, Lundervold A. An overview of deep learning in medical imaging focusing on MRI. Z Med Phys 2019; 29:102-127. [DOI LINK]
Maier A, Syben C, Lasser T, Riess C. A gentle introduction to deep learning in medical image processing. Z Med Pay 2019; 29:86-101. [DOI LINK]
Moawad AW, Fuentes DT, ElBanan MG, et al. Artificial intelligence in diagnostic radiology: where do we stand, challenges, and opportunities. J Comput Assist Tomogr 2022; 46:78-90. [DOI LINK]
Nicholson C. A beginner’s guide to LSTMs and recurrent neural networks. In: A.I. Wiki. A beginner’s guide to important topics in AI, machine learning, and deep learning. (Downloaded from wiki.pathmind.com 13 Jan 2022)
Siddique N, Paheding S, Elkin CP, Devabhaktuni V. U-Net and its variants for medical image segmentation: a review of theory and applications. IEEE Access 2021:82031-82057. [DOI LINK]
Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need. (2017-6-12). arXiv1706.03762. [DOI LINK] (Original paper describing Transformers)
Willemink MJ, Roth HR, Sandfort V. Two foundational deep learning models for medical imaging in the new era of Transformer Networks. Radiology: Artificial Intelligence 2022; 4(6):e210284. [DOI LINK]
Wolterink JM, Mukhopadhyay A, Leiner T, et al. Generative adversarial networks: a primer for radiologists. RadioGraphics 2021; 41:840-857. [DOI LINK]
Yi Xin, Babyn PS. Generative adversarial network in medical imaging: a review. Medical Image Analysis 2019; 58:101552. [DOI LINK]
Related Questions
Is artificial intelligence the same as machine learning?
I still don't understand how machines learn. How do they "reprogram" themselves?
Is artificial intelligence the same as machine learning?
I still don't understand how machines learn. How do they "reprogram" themselves?