Shallow Neural NetworksWhy would one use a shallow neural network? What are the various types?
|

|
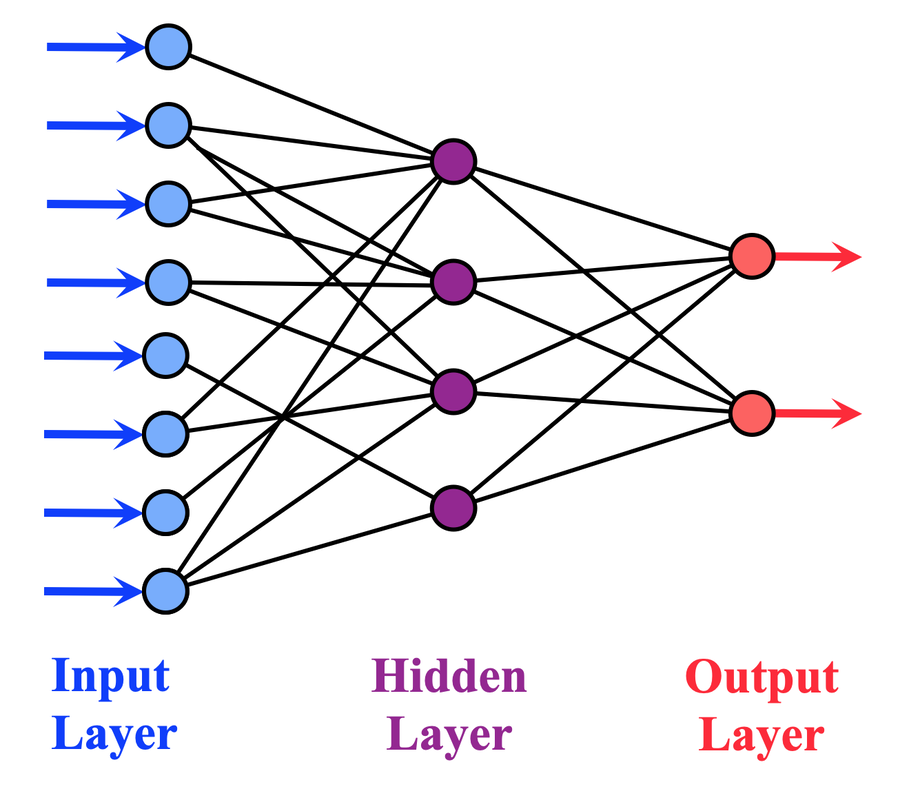 Shallow Neural Network
Shallow Neural Network
As described in the prior Q&A, a shallow neural network has only one (or just a few) hidden layers between the input and output layers. The input layer receives the data, the hidden layer(s) process it, and the final layer produces the output. Shallow neural networks are simpler, more easily trained, and have greater computational efficiency than deep neural networks, which may have thousands of hidden units in dozens of layers. Shallow networks are typically used for simpler tasks such as linear regression, binary classification, or low-dimensional feature extraction.
Technically speaking, a neural network with more than one hidden layer is no longer considered a shallow neural network. In some cases, however, a neural network with 2 or 3 hidden layers, each with a small number of hidden units and having simple connectivity between them may produce straightforward outputs and may still be considered a "shallow" network.
Four common shallow ML techniques are used in image processing applications for MRI, illustrated and discussed below.
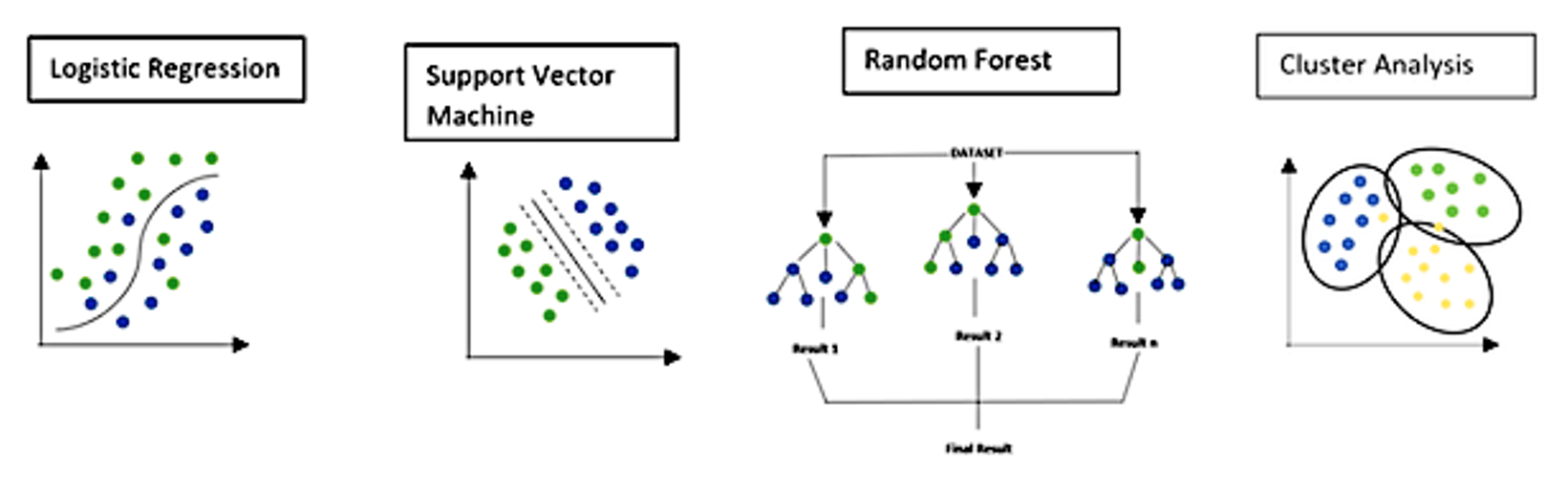
Various Shallow Neural Networks (modified from Argentiero et al under CC BY)
Logistic Regression
Logistic regression is a shallow supervised ML technique most commonly used to solve classification problems, especially where the outcome is binary, such as (A or B), (yes or no), and (malignant or benign). Logistic regression is similar to the more familiar linear regression, except that in the latter the output can take on any value. In logistic regression the output is constrained to just two (or at most a few) discrete values. At the heart of logistic regression lies the logistic function, f(x) = 1 / (1 + e−x), which has a sigmoidal shape and returns a value between 0 and 1 for all inputs x.
|
During training, the system is provided with correctly classified cases, each described by one or more inputs. The logistic regression algorithm then calculates linear combinations of the inputs and optimizes parameters via a maximum likelihood method that generates odds ratios close to either 0 or 1, depending to which binary class the inputs correspond. Once the parameters are optimized, the model can be used to classify outcomes when new unknown data are presented.
|
|
Support Vector Machine (SVM)
In a SVM data is segregated into two classes, each represented by points in space separated by as large a distance as possible. A dividing boundary separates the classes. The choice of the boundary is taken as the one that maximizes the distance (the "margin") between the boundary and the closest point in each group. In other words, the best boundary is the one that cleanly divides the data but doesn't approach either group too closely. The data points lying closest the boundary are called the support vectors. They represent the points most difficult to classify and have a direct bearing on the optimal position of the boundary.
|
|
For simple classification problems the boundary is just a straight line or plane. In more complex cases it may be necessary to construct a non-linear boundary such as a parabola, circle, or hyperplane. This is performed by transformation of the data into a higher dimension using a so-called kernel function.
|
Like logistic regression, the optimal boundary in SVM is calculated using a training set whose classifications and inputs are known. New cases are then classified as to which side of the boundary they fall. SVM methods may be extended to more than two classes (albeit with some difficulty).
Random Forest
The Random Forest is a machine learning technique for classification and prediction of data. The building block of the Random Forest is the Decision Tree.
|
Decision trees are relatively straightforward and simple to construct. For example, a decision tree for classifying a ball as football, golf ball, or tennis ball might include two initial branches dealing with shape (round or oblong), with two additional branches along the round into and size (larger or smaller than 4 cm). The major problem with simple decision trees is their high variance -- they commonly overfit the data and do not generalize well to samples beyond the training set.
|
|
Random Forests were developed to overcome these problems. Instead of a single tree, Random Forests consist of a large ensemble of individual trees constructed using a randomly selected data from subsets of the original variables. Once the trees are constructed they are tested with known data and the various trees in the forest are scored for their accuracy in prediction. They can thus be used to rank the most important variables in the data. Additional advantages include insensitivity to outliers, ability to handle new data without changing dramatically, and ability to handle missing data.
Cluster Analysis
Unlike the three supervised machine learning techniques above, Cluster Analysis is unsupervised. Its goal is to subdivide large data sets into clusters, groups of objects that have similar properties or features compared to other groups.
|
|
Popular clustering methods used imaging applications include:
|
References
Argentiero A, Muscogiuri G, Rabbat MG, et al. The applications of artificial intelligence in cardiovascular magnetic resonance — a comprehensive review. J Clin Med 2022; 111:2866. [DOI LINK]
Breiman L. Random forests. Machine Learning 2001; 45:5-32. (original description of the technique).
Cluster Analysis. Wikipedia, The Free Encyclopedia. (accessed 7-16-22)
Levy JJ, O’Malley AJ. Don’t dismiss logistic regression: the case for sensible extraction of interactions in the era of machine learning. BMC Medical Research Methodology (2020) 20:171. [DOI LINK]
Noble WS. What is a support vector machine? Nature Biotechnology 2006; 24:1565-7. [DOI LINK]
Seif G. The 5 clustering algorithms data scientists need to know. Toward Data Science, 2018;1-10.
Downloaded 7-16-22 from this link. (Recommend viewing online as it contains multiple animated gifs).
Argentiero A, Muscogiuri G, Rabbat MG, et al. The applications of artificial intelligence in cardiovascular magnetic resonance — a comprehensive review. J Clin Med 2022; 111:2866. [DOI LINK]
Breiman L. Random forests. Machine Learning 2001; 45:5-32. (original description of the technique).
Cluster Analysis. Wikipedia, The Free Encyclopedia. (accessed 7-16-22)
Levy JJ, O’Malley AJ. Don’t dismiss logistic regression: the case for sensible extraction of interactions in the era of machine learning. BMC Medical Research Methodology (2020) 20:171. [DOI LINK]
Noble WS. What is a support vector machine? Nature Biotechnology 2006; 24:1565-7. [DOI LINK]
Seif G. The 5 clustering algorithms data scientists need to know. Toward Data Science, 2018;1-10.
Downloaded 7-16-22 from this link. (Recommend viewing online as it contains multiple animated gifs).
Related Questions
Is artificial intelligence the same as machine learning?
Is artificial intelligence the same as machine learning?